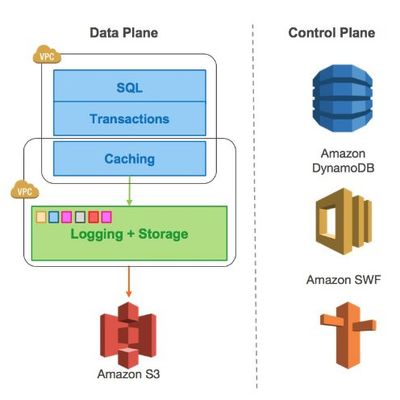
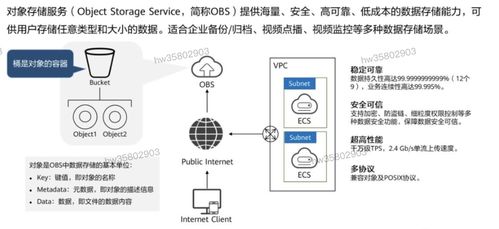
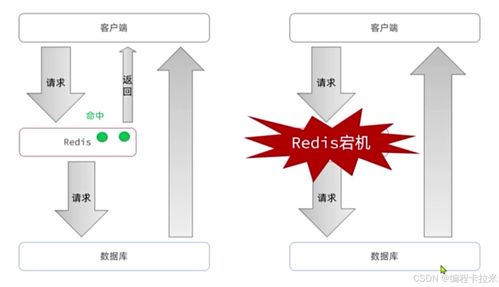
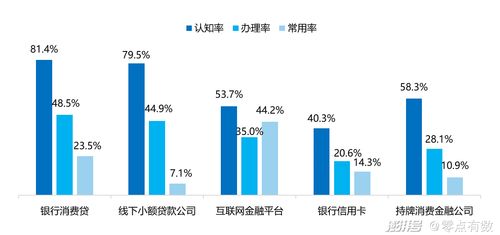
解决数据处理后TXT文件格式错乱 空格间距问题分析
在数据处理和存储服务中,许多用户会遇到一个常见但令人困惑的问题:将TXT文件中的数据经过处理(如读取、修改、清洗或转换)后,再次保存为TXT文件时,文件的格式出现错乱。具体表现为各行之间的空格间距变得混乱,原本对齐的文本变得参差不齐,影响可读性和后续使用。本文将深入分析这一问题的成因,并提供有效的解决方案。
问题成因分析
- 编码不一致:在读取和写入TXT文件时,如果使用的字符编码(如UTF-8、GBK、ASCII等)不一致,可能导致空格字符(特别是全角与半角空格)被错误解析或转换。例如,一个在UTF-8编码下的空格,在以GBK编码写入时可能变成乱码或不同宽度的字符,从而打乱间距。
- 制表符与空格混淆:TXT文件中常使用制表符(Tab,\t)和空格(Space)进行对齐。数据处理过程中,如果程序未正确处理这两种字符的区别,可能会将制表符转换为多个空格,或将多个空格合并为制表符,导致原有间距失效。例如,一个制表符原本代表4个空格的宽度,但处理后被替换为2个空格,就会使对齐错位。
- 行尾符差异:不同操作系统使用不同的行尾符(Windows用\r\n,Linux/macOS用\n)。数据处理时,如果行尾符被意外修改或删除,可能影响文本的换行和间距显示。某些编辑器或程序在读取时会自动转换行尾符,保存时却未还原,造成格式混乱。
- 数据处理逻辑错误:在清洗或转换数据时,代码可能无意中删除了多余空格,或添加了不必要的空格。例如,使用字符串处理函数(如Python的
strip()或replace())时,若未考虑上下文,可能移除用于对齐的空格,导致各行长度不一。
- 字体或查看工具问题:有时,文件本身格式正确,但用不同的文本编辑器(如记事本、VS Code、Sublime Text)打开时,因字体或渲染设置不同,空格显示宽度可能不一致,造成“看起来”错乱的错觉。这需要检查原始文件内容是否真的被修改。
解决方案与最佳实践
针对上述成因,我们可以采取以下措施来避免或修复格式错乱问题:
- 统一编码标准:在读取和写入TXT文件时,始终明确指定相同的字符编码。例如,在Python中,使用
open(file, 'r', encoding='utf-8')和open(file, 'w', encoding='utf-8')确保一致性。建议优先使用UTF-8编码,因为它广泛兼容且支持多语言字符。
- 规范空格与制表符:在数据处理前,先分析文件中的对齐方式。如果依赖制表符,请在代码中保留制表符;如果使用空格,则固定空格数量(如用4个空格替代制表符)。可以使用正则表达式或专用库(如Python的
textwrap)来标准化空白字符。例如,将所有制表符替换为固定数量的空格:text = re.sub('\t', ' ', text)。
- 处理行尾符:根据目标操作系统,统一行尾符。在保存文件时,可以显式指定行尾符格式。例如,在Python中,写入时使用
'\n'作为通用换行符,或根据系统用os.linesep。
- 优化数据处理逻辑:在修改文本内容时,避免盲目删除空格。可以先标记或备份原始格式,或在处理完成后重新对齐数据。对于结构化数据(如表格),考虑使用CSV或JSON格式代替纯文本,以更好地保持结构。
- 验证与测试:处理前后,使用十六进制查看器或编程工具检查文件实际内容,确认空格、制表符和行尾符是否如预期。例如,在Linux下用
cat -A命令显示隐藏字符,或在Python中打印字符的ASCII值。
实际应用示例
假设我们有一个TXT文件data.txt,内容为表格形式,用空格对齐。在Python中处理并保存后格式错乱,我们可以这样修复:
`python
import re
读取时指定编码,并保留原始空白
with open('data.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
处理数据:例如,清洗内容但不改变对齐空格
processed_lines = []
for line in lines:
# 假设我们只修改非空格部分,如移除多余字符
cleaned_line = re.sub('[^\w\s]', '', line) # 去除非字母数字和空格的字符
# 保持原有空格间距:这里简单保留原样,或根据需求调整
processedlines.append(cleanedline)
写入时使用相同编码和行尾符
with open('processeddata.txt', 'w', encoding='utf-8', newline='\n') as f:
f.writelines(processedlines)`
通过以上方法,我们可以有效维持TXT文件的格式完整性。在数据处理和存储服务中,注意细节和一致性是避免格式错乱的关键。如果问题持续,建议检查整个数据流水线,从读取到处理的每个环节,确保无缝衔接。
如若转载,请注明出处:http://www.24zhidao.com/product/43.html
更新时间:2026-06-19 05:07:02