AI大模型时代的数据处理与存储服务 张亚勤的洞察与展望
在人工智能大模型快速发展的背景下,数据处理和存储服务成为技术演进的核心支柱。张亚勤,作为人工智能领域的资深专家,强调了这一领域的关键作用。他指出,AI大模型的训练和推理依赖于海量、高质量的数据,而高效的数据处理与存储服务是确保模型性能、可扩展性和安全性的基础。
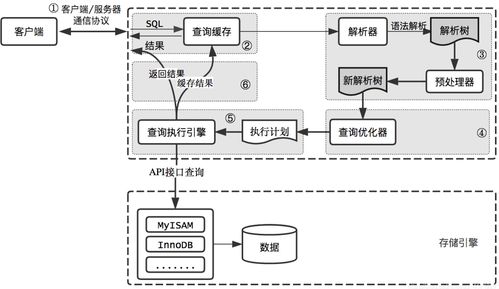
数据处理服务在大模型时代面临着前所未有的挑战。大模型需要从多源异构数据中提取特征,涉及数据清洗、标注、增强和联邦学习等环节。张亚勤提到,传统的数据处理方法已难以满足需求,必须引入分布式计算、边缘计算和实时流处理技术,以提升数据吞吐量和处理效率。数据隐私和合规性问题也日益突出,推动了对差分隐私、同态加密等前沿技术的应用。
存储服务在支撑大模型生命周期中扮演着关键角色。从原始数据到训练中间结果,再到模型部署,存储系统需具备高可用性、低延迟和高可扩展性。张亚勤强调,云原生存储和对象存储方案正成为主流,它们通过弹性资源分配,帮助企业降低总拥有成本。同时,随着模型规模的扩大,对存储介质的性能要求也在提升,例如采用NVMe和持久内存技术来加速数据访问。
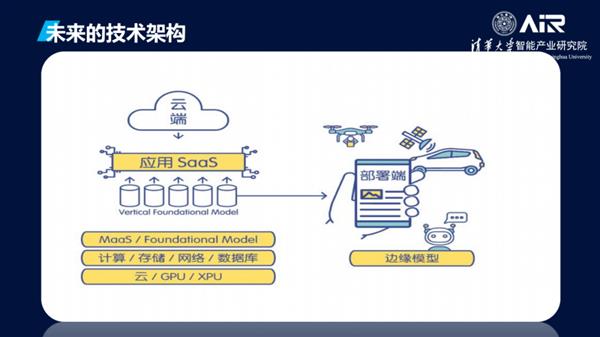
张亚勤认为,数据处理和存储服务将进一步与AI技术融合,催生智能数据管理平台。这些平台将集成自动化数据治理、智能数据湖和跨云存储能力,为企业和开发者提供端到端解决方案。他还呼吁行业加强合作,制定统一标准,以应对数据安全和伦理挑战。
在AI大模型时代,数据处理和存储服务不仅是技术基础设施,更是创新驱动力的引擎。张亚勤的见解提醒我们,投资于这一领域,将助力全球AI生态的可持续发展。
如若转载,请注明出处:http://www.24zhidao.com/product/14.html
更新时间:2026-04-14 17:56:56